n-waves.github.io
Business applications of Natural Language Processing (NLP)
autor: Barbara Jastrzebska
Is it possible for a computer to understand text or speech as humans do? And then translate it into another language?
History of natural language processing (NLP) goes back to the 1950s when the first trials of fully automatic translation from Russian into English took place. And it failed pitifully. Machines of that time could not cope with the interpretation of the context of what the infamous example was the biblical "The spirit is willing, but the flesh is weak” translated as “vodka is good, but the meat is rotten”. But despite its difficult beginnings NLP is fine and is useful in business. Here are some examples that we think you might find handy.
Sentiment Analysis
Area of application: Customer service (performance monitoring), Marketing (brand monitoring)
It’s not a secret that companies actively monitor their online presence. As consumers talk about brands and companies through social media platforms, and often submit their complaints there - Twitter, Snapchat, Instagram, Facebook monitoring has become a great opportunity and challenge for companies.
Sentiment analysis which detects the emotional state and the attitude of the writer can be a helpful tool for them. It’s achieved by either assigning a polarity to the text (neutral, positive or negative) or detecting the mood (sad, happy, angry, etc). In the case when ambivalent or multiple attitudes appear in the same sentence, the text may be split into clauses and polarity and mood are assigned to each one separately. For example “This restaurant is nice, but the staff is rude.”
{
“clause”: “This restaurant is nice”,
“polarity”: 0.92,
“mood”: “happy”
},
{
“clause”: “but the staff is rude!”,
“polarity”: -0.95,
“mood”: “angry”
}

Even though we can get quite a high accuracy on sentiment analysis on specific sets of texts it is not possible yet to build a universal sentiment detector. To obtain high accuracy it is best to train models on your own annotated data. Fortunately, this step can be quickly achieved with either Amazon Mechanical Truck or even better by your team using tools like Prodigy that significantly speeds up the process by showing you only the examples were your sentiment model is the least sure about. This area of NLP received quite a performance boost in early 2018 when the researchers found out how to use transfer learning. We will devote another article to give you more details and briefly discuss the performance of sentiment models in different European languages.
Named Entity Recognition (NER)
Area of application: brand monitoring, customer satisfaction research, journalism, finances
As we already know companies need to go far beyond their internal data to have their fingers on the pulse. Online text source like social media posts, forums, public reports, blogs, online newspapers and many others contain plenty of information which extracted and ordered, can give valuable insight on you and your competition. It is where NER can be useful. NER annotates text marking occurrences of named entities (a term coined by researchers to refer to names of persons, organisations, locations, expressions of times, quantities, monetary values, percentages, etc.).
For example the following text:
“n-waves won the first price in PolEval 2018.”
would be annotated as follows:
“[n-waves]ORG won the [first price]AWARD in [PolEval]ORG [2018]TIME.”
And the following information could get extracted:
Org: n-waves
Award: first price
Org: PolEval
Time: 2018
This step dramatically simplifies downstream task like content categorisation and tagging, text summarisation, it helps as well search engines to become more accurate.
We see this technique being used in customer support and brand monitoring as a first task to categorise gigabytes of customer feedback and associate it with a product and/or a company it refers to. This information later can be used to automatically classify user messages or apply sentiment analysis to obtain practical scores about the companies and their competition.
Unfortunately, as most of the Natural Language Processing tasks, NER is quite brittle, which means that a highly accurate model trained on one particular stream of data like Twitter won't work that well with texts from a different domain like news articles or customer forums. So to achieve highly accurate models the best is to use your own data. Fortunately, as in the case of sentiment analysis, the same tools can help you quickly add relevant text annotations.
Text summarisation
Area of application: HR, law and insurances, healthcare and more
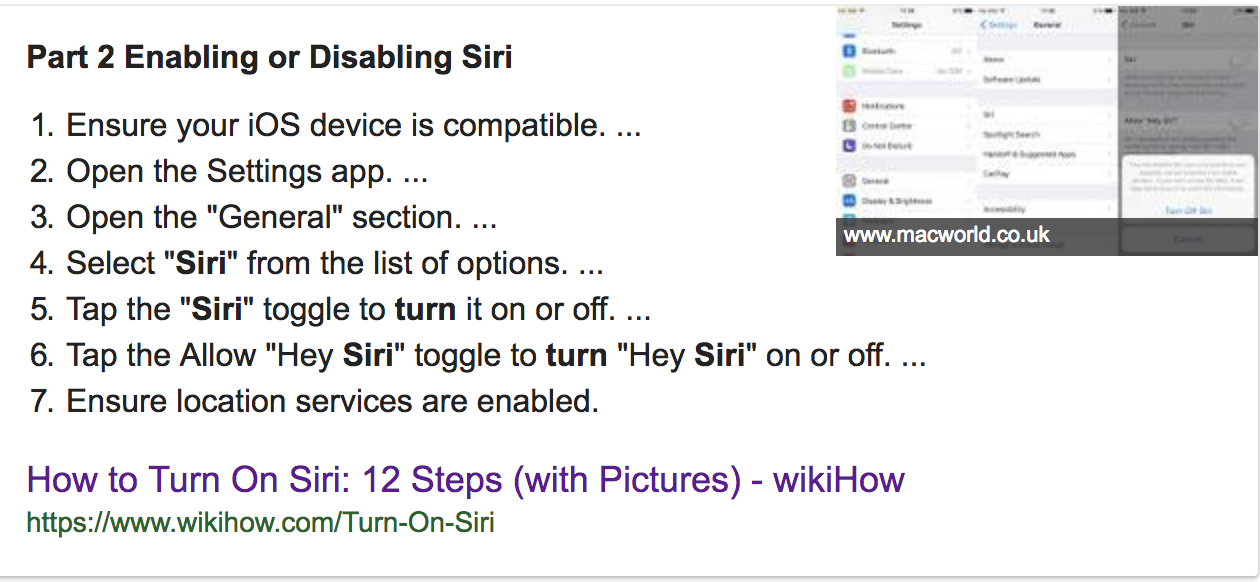
Above example of text summarisation by google. The article How to turn on Siri:12 steps extracted and summarised in 7 points.
Long documents shortened to the elegant and concise abstract. Thanks to NLP you don’t need to lie over the volumes of files. There are two approaches to this task – extraction and abstraction. An extraction-based approach will find the most important parts of the text, (sentences or the whole paragraphs) and build the summary out of them. An abstraction-based approach goes even further. The computer doesn’t merely copy the significant parts but writes the brief in its own words, just like a human would do. This approach is still under active research though, and however close we are, today extraction approach is the one in daily use.
There are several real-world application for this technique. The obvious one is google and other search engines. You see the text summarisation in every result page. But there are more subtle applications. Imagine how with text summarisation the doctor can quickly get a summary of a medical profile of each of his numerous patients based on their medical check-ups and test results. Or how it can help lawyers to go through ever-changing law regulations to extract some relevant rules that concern their clients.
Fortunately, the text summarisation based on extraction is a mostly solved problem, and you can apply existing software like ElasticSearch reasonably quickly. However, if you’re looking at some more sophisticated use case where text generation is required you need quite a few examples. If you are a sizeable law office, there is a good chance that you already have the data that is needed at hand, from your past engagement. In other cases, where you have to generate the training examples yourself, there are no shortcuts and your best bet is to do it or employ a company like Amazon Mechanical Truck.
NLP is still young, but promising field. Not everything works yet, but the development is intensive and with recent advancement in deep learning, we see vast improvements discovered every month. It will take a while until computers start to understand the texts on par with humans. But even though its limitations NLP is a valuable technology with plenty of useful business applications.
Photo by 수안 최 on Unsplash